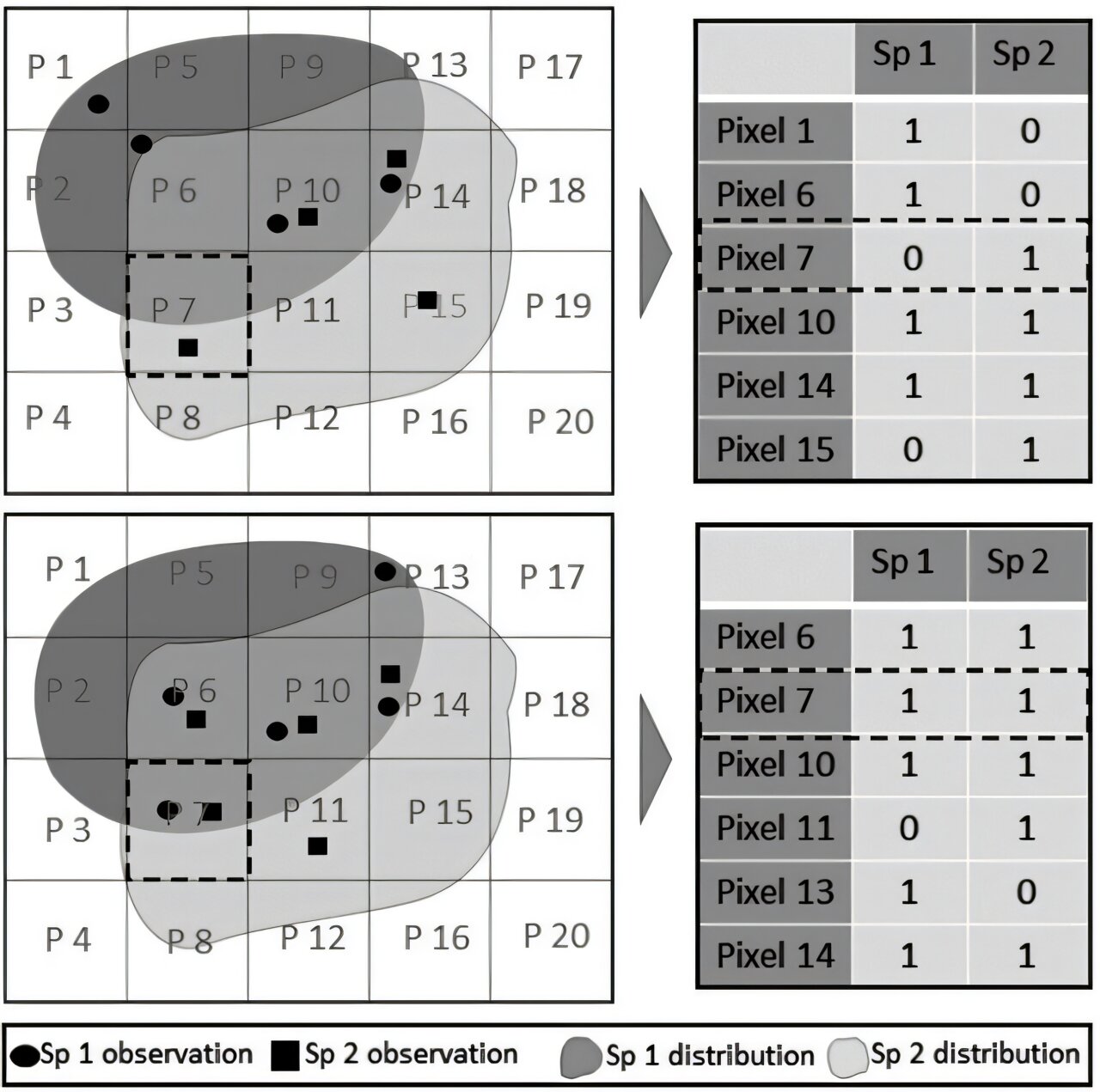
 co-occurring species (light and dark grey polygons; Sp1 and Sp2) can be derived into community matrices (right tables) by aggregating observations (square and circle symbols) at specific locations (i.e. pixels—P) and assuming unobserved species as absences. The figure illustrates two different realizations of observations simulating opportunistic databases (top and bottom illustrations). In the example at the top, the random sampling of both species results in a selection of pixels that more or less capture a co-occurrence pattern representative of reality. In the example at the bottom, the sampling of both species is biased towards areas of co-occurrence leading to a community matrix with a higher degree of co-occurrence between the two species. In both examples, there are omission errors for one (e.g. species 1 at pixel 7 and species 2 at pixel 6 in the example at the top, or species 2 at pixel 13 in the example at the bottom) or both species (e.g. both species at pixel 9 in both examples). Credit: Ecography (2024). DOI: 10.1111/ecog.07340")
A team at the University of Córdoba verifies that large biodiversity databases, in which citizens record observations of flora, are capable of calibrating joint species distribution models, even when conducted individually, provided that more than 50% of the species in the area have been recorded.
In the current context of climate change, institutions and the scientific community are pondering how new climatic conditions will affect species of wild flora. For example, how will populations of Spanish fir (Abies pinsapo) change? This is an endangered species that the Junta de Andalucía (regional government) is tracking, with protection plans in place.
To predict whether in the future the Spanish fir tree will grow in mountain areas higher than those where they are now found, the weather must be taken into account, but for those predictions to be more accurate, the relationships between different species must also be included in the mathematical models used to forecast these future scenarios. The positive or negative relationships between different species will be decisive in predicting their future distribution.
Therefore, the research community is shifting from mathematical models of species distribution that only take into account environmental variables (climate, soil type) to community ones offering maps that take into consideration both climatic variables and also relationships between plants. That is, they are moving from an individualistic approach to a community one to produce better predictions. However, there is little flora data including the composition of the biological communities with which to build these models, as collection is based on plant-by-plant recording.
Faced with this problem, researchers Diego Nieto and Daniel Romera with the University of Córdoba’s Basic and Applied Plant Biology Group, carried out a first analysis of the use of opportunistic biodiversity databases (unstructured ones containing individual data from citizen observations) in joint species distribution models. The paper is published in the journal Ecography.
“In principle, these databases shouldn’t be used to calibrate community models, because they feature individual observations that do not take into account the relationship between species, but we wondered whether, by having billions of records, they could work, getting the models to give us predictions considering the relationships between species,” explained researcher Nieto.
After calibrating the model with this type of individual data with different types of coverage (simulating more or fewer records of the reality of the species in an area) they obtained two results: the model made accurate predictions of the distribution according to climatic variables, despite having little data, and also managed to predict inter-species interactions as long as 50% to 75% of the species were recorded.
How did they verify this?
Taking into account that the real databases used, such as GIBIF, which contains more than three billion units of biodiversity data, recorded through applications such as iNaturalist, are not always well recorded, and it is not known whether part of the reality that is not recorded is being lost, the researchers created an artificial database for the experiment, so that they could then confirm whether the model functioned correctly.
Nieto explained, “We came up with a study area, the distribution of 10 different species, and simulated different levels of coverage of each one’s actual distribution. In one scenario, 10% of all the places where the species is found were sampled; in others, 25%, 50%, 90% and 100%. That is, with the different options of how well represented the reality would be using the data recorded in these databases.”
By working with this generated data, they were able to ascertain the model’s response very well, and then use it with the existing individual databases.
The model calculates the interactions between species, provided that it already has at least 50% to 75% of the species’ total locations, and can offer accurate predictions of how communities of species will behave in the face of future climate change scenarios.
“The results are encouraging, as the model is able to calculate interactions even if you don’t have 100% of the recorded data on the species,” the researchers concluded.
How do they know whether those databases contain at least 50% of the records of the reality of the species? To do this, they used a method that evaluates the integrity of real data at the pixel level using a case study of forest trees in Europe, comparing the number of observations in a pixel of the database with the total number of species observed in that pixel. When there are many observations for few species, this indicates that it is better sampled. The higher the data level, the better it depicts the reality.
This analysis presents a mechanism to select which information from the databases should be used to calibrate these community models and make better predictions about wild plant species patterns.
More information:
Daniel Romera‐Romera et al, Should we exploit opportunistic databases with joint species distribution models? Artificial and real data suggest it depends on the sampling completeness, Ecography (2024). DOI: 10.1111/ecog.07340
Provided by
University of Córdoba
Citation:
Massive biodiversity data collection improves ecosystem predictions (2024, October 22)
retrieved 22 October 2024
from https://phys.org/news/2024-10-massive-biodiversity-ecosystem.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.